filmarksの映画レビューをスクレイピング2
前回Filmarksに対して最も単純なスクレイピングを実践した。しかし同じ方法でMarks(その映画を見た人の数)やCalips(その映画を見たいと思っている人の数)を取得しようとすると、ブラウザで見えるHTMLの通りにデータを取得することができない。
理由はこちら。
そこでブラウザを直接操作できるSeleniumというツールを使用する。Rだと{RSelenium}というパッケージがある。
参考にしたのは宇宙の本の第2章。
まずは必要なパッケージ等のインストール。
#環境構築
install.packages("RSelenium")
library(wdman)
selenium(retcommand = TRUE)ここで、JAVAがないからエラーですと表示されたので、JDKをダウンロード&インストール。必要な設定をしたらエラーはなくなった。
PythonでスクレイピングをしたときはChromeDriverをダウンロードしたりしたがそのあたりを上記のコマンドで一通りやってくれるのだそう。
#パッケージの読み込み
library(RSelenium)
#chromeブラウザを立ち上げる
rD <- rsDriver(verbose = FALSE, chromever = "88.0.4324.96") #port= 4837L
#remoteDriverクラスの作成
remDr <- rD[["client"]]chromeverはデフォルトで最新になっているが自分のchromeは最新版なのに88だったのでここで指定。バージョンのオプションは#binman::list_versions("chromedriver")で確認できる。
あと、Seleniumサーバーは2回以上使用すると「Selenium server signals port = 4567 is already in use.」というメッセージが表示されるが、適当なportを指定するかRstudio(R)を再起動すればよい。
で、ブラウザを直接操作できる状態で前回と同様のこととするだけ。navigate()関数を使う。
#結果を入れるハコ
data <- data.frame()
for(i in 1:101){
fil_url <- paste0("https://filmarks.com/list/year/2020s/2020?page=",i)
remDr$navigate(fil_url)
#htmlを読み込むがリスト形式なのでベクトルに変換する。
planeHtmlList <- remDr$getPageSource()
planeHtml <- unlist(planeHtmlList)
title <- read_html(planeHtml) %>%
html_nodes(css = ".p-content-cassette__title") %>%
html_text()
marks <- read_html(planeHtml) %>%
html_nodes(css = ".p-content-cassette__action.p-content-cassette__action--marks") %>%
html_text()
clips <- read_html(planeHtml) %>%
html_nodes(css = ".p-content-cassette__action.p-content-cassette__action--clips") %>%
html_text()
score <- read_html(planeHtml) %>%
html_nodes(xpath = "//div[@class = 'p-content-cassette__info']//div[@class = 'c-rating__score']") %>%
html_text()
temp <- data.frame(title=title, marks=marks, clips=clips, score=score)
data <- bind_rows(data,temp)
#寝る。ブラウザを操作するのでちょっと長め。
Sys.sleep(3)
}終わったらちゃんと片づける。
#ブラウザを閉じる
remDr$close()
#Seleniumサーバを閉じる
rD[["server"]]$stop()これで取得完了。相変わらず文字になっているので加工する。
data_clean <- data %>%
mutate(marks=as.numeric(gsub(marks,pattern="-",replacement = "0", ignore.case = TRUE))) %>%
mutate(clips=as.numeric(gsub(clips,pattern="-",replacement = "0", ignore.case = TRUE))) %>%
mutate(score=as.numeric(gsub(score,pattern="-",replacement = "0", ignore.case = TRUE)))また、100人超に評価されている作品のみに絞って可視化することにした。
data_over100 <- data_clean %>%
filter(marks > 100)
p1 <- ggplot(data_over100,aes(x=score))
p1 + geom_histogram(breaks=seq(0,5,0.1))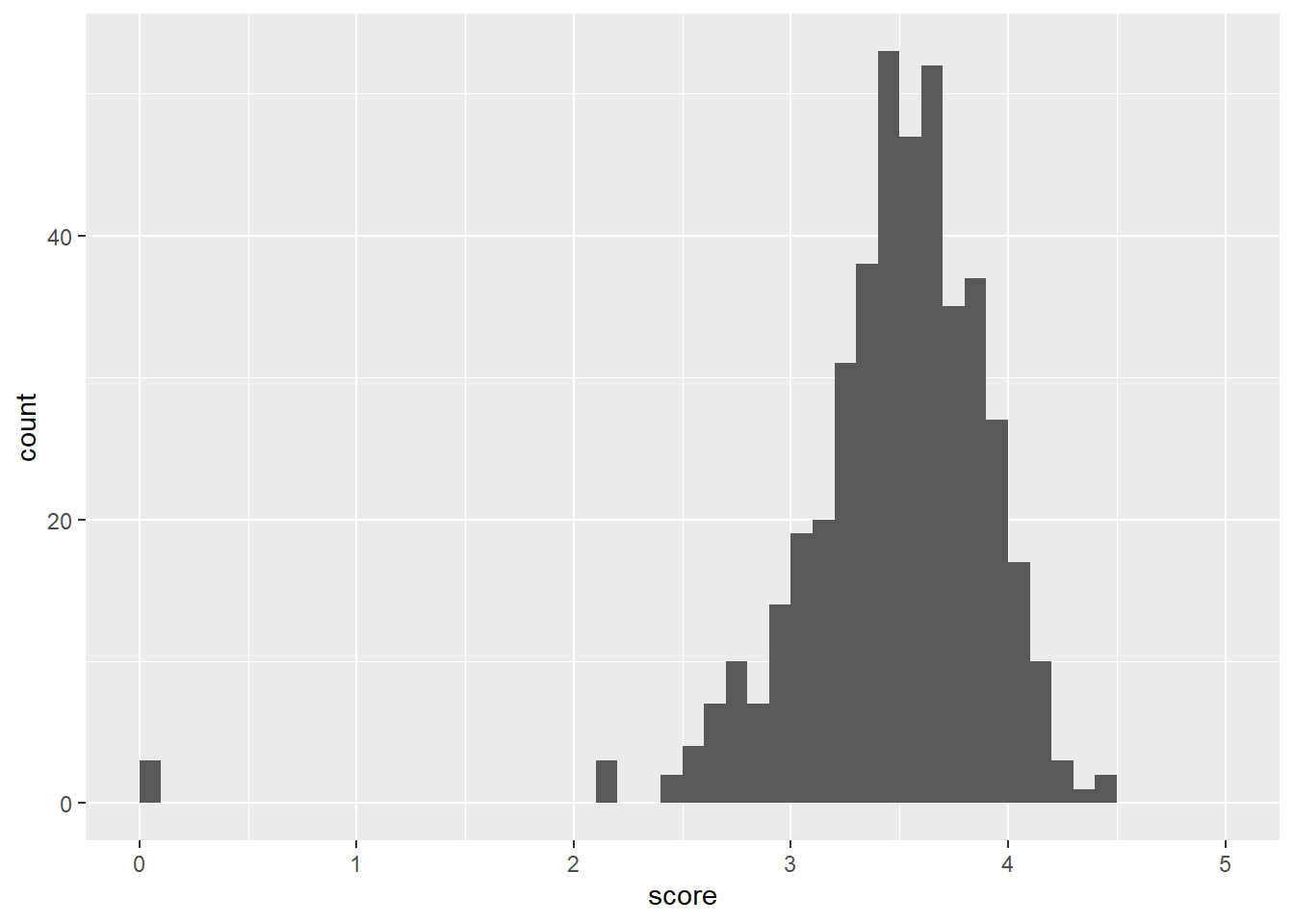
だいぶ作品数減った。やはり最頻値は3.5。0が3件あるのは未公開の作品になぜかマークしてる人が100人超いたから。
p1 <- ggplot(data_clean,aes(x=score,y=marks))
p1 + geom_point()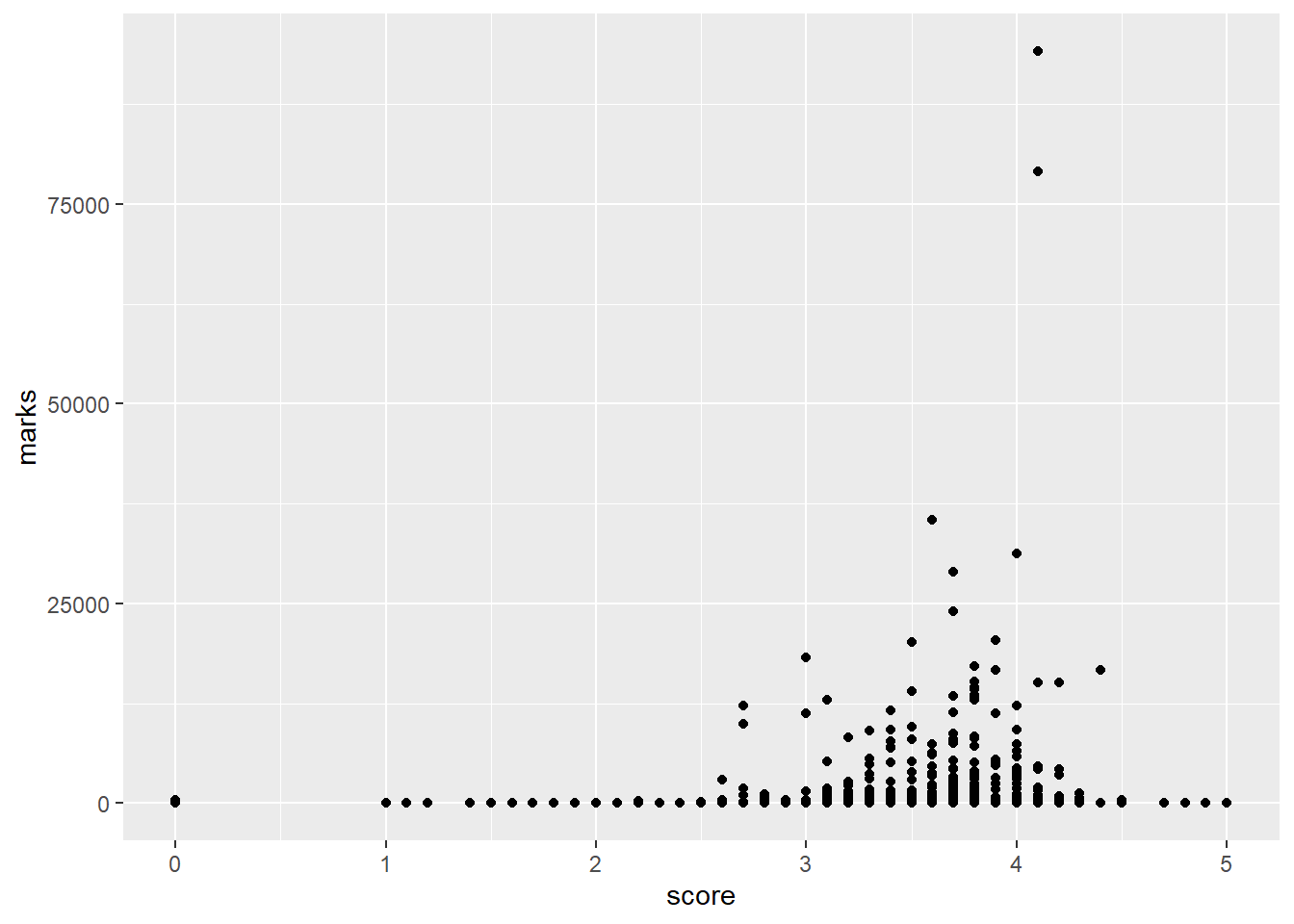
スコアとマークの散布図。2トップはテネットと鬼滅。1万人以上にレビューされて3点未満の作品もあるのね。
data_over100 %>%
arrange(desc(score))## # A tibble: 442 x 4
## title marks clips score
## <chr> <dbl> <dbl> <dbl>
## 1 ハミルトン 240 953 4.5
## 2 KING OF PRISM ALL STARS プリズムショー☆ベストテン 391 98 4.5
## 3 劇場版 ヴァイオレット・エヴァーガーデン 16702 17120 4.4
## 4 BREAK THE SILENCE: THE MOVIE 1275 471 4.3
## 5 Reframe THEATER EXPERIENCE with you 659 354 4.3
## 6 蒼穹のファフナー THE BEYOND 第七話・第八話・第九話 128 96 4.3
## 7 ミッドナイトスワン 15050 29399 4.2
## 8 僕たちの嘘と真実 Documentary of 欅坂46 3480 1950 4.2
## 9 オクトパスの神秘: 海の賢者は語る 214 147 4.2
## 10 映画 ギヴン 837 935 4.2
## # ... with 432 more rowsdata_over100 %>%
arrange(score)## # A tibble: 442 x 4
## title marks clips score
## <chr> <dbl> <dbl> <dbl>
## 1 キングスマン:ファースト・エージェント 433 59474 0
## 2 シン・エヴァンゲリオン劇場版 342 26151 0
## 3 トップガン マーヴェリック 130 15400 0
## 4 マーク・オブ・ザ・デビル 234 44 2.2
## 5 君は彼方 136 642 2.2
## 6 Le Cerveau - セルヴォ - 117 7 2.2
## 7 別れる前にしておくべき10のこと 207 200 2.5
## 8 巨蟲列島 122 106 2.5
## 9 シグナル100 2894 2608 2.6
## 10 『犬鳴村』恐怖回避ばーじょん 劇場版 328 508 2.6
## # ... with 432 more rowsで、見たかった上位と下位。ハミルトンはアメリカ合衆国建国の父の1人アレキサンダーハミルトンについてのミュージカルを映画化したもの。1万人以上に評価されて4.4のヴァイオレット・エヴァーガーデンはアニメの映画化らしい。
ミッドナイトスワン良さそうだな。見てみるか。
下位のトップ3は前述の未公開作品。4位5位あたり、気になる。見ないけど。